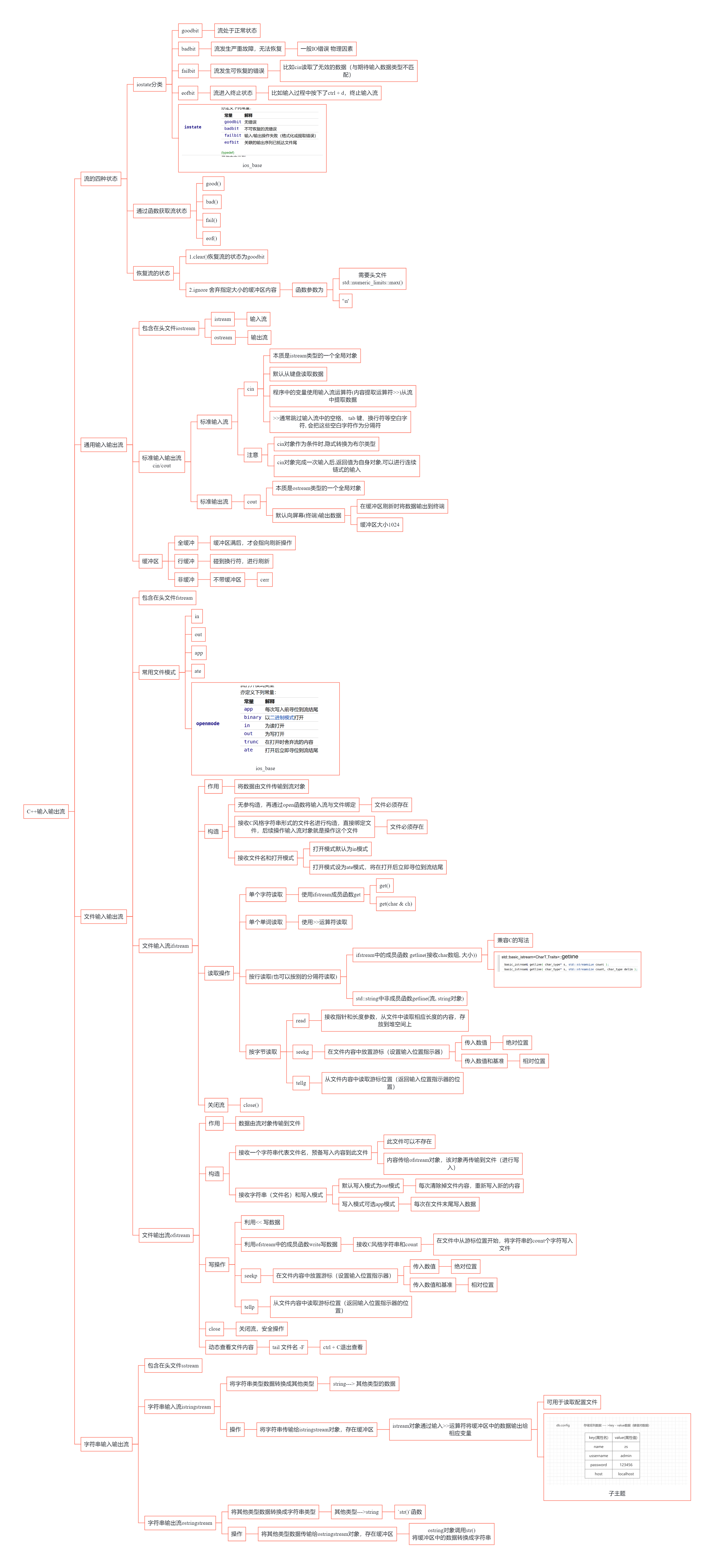
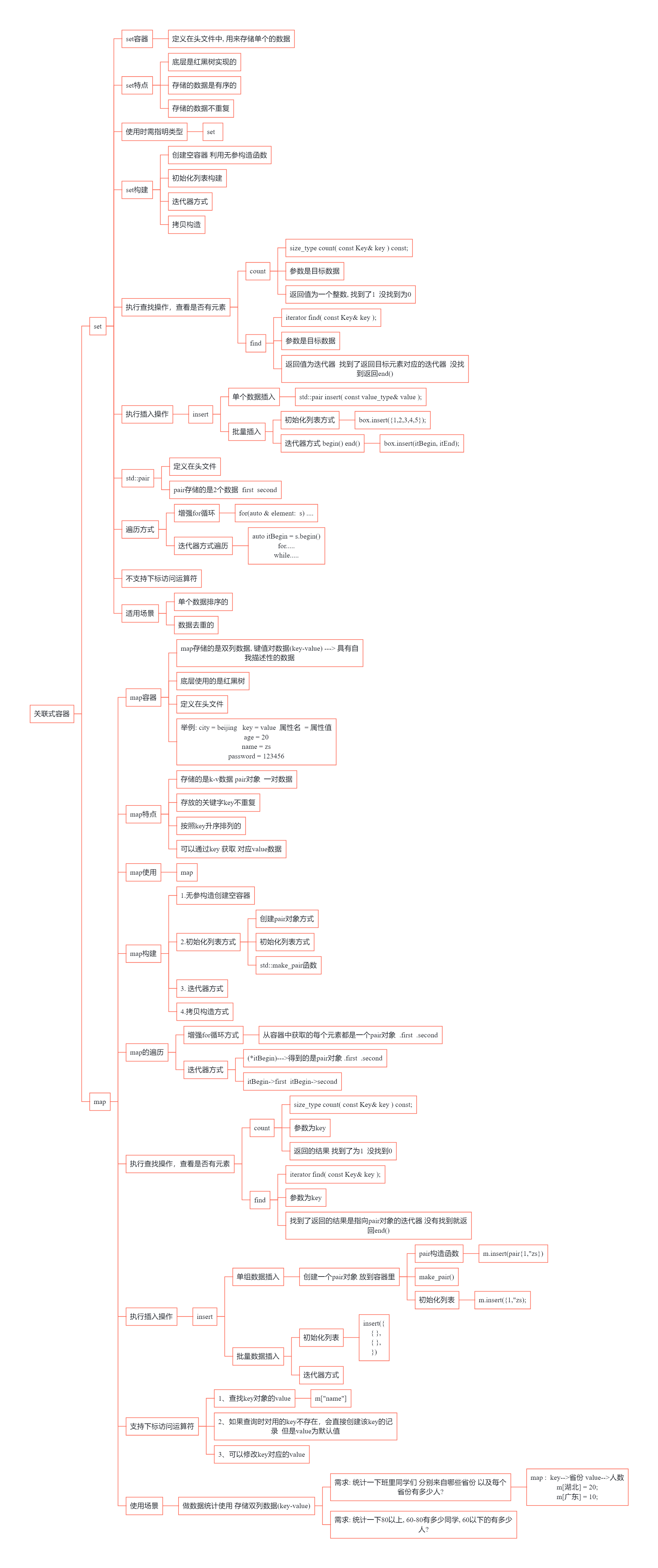
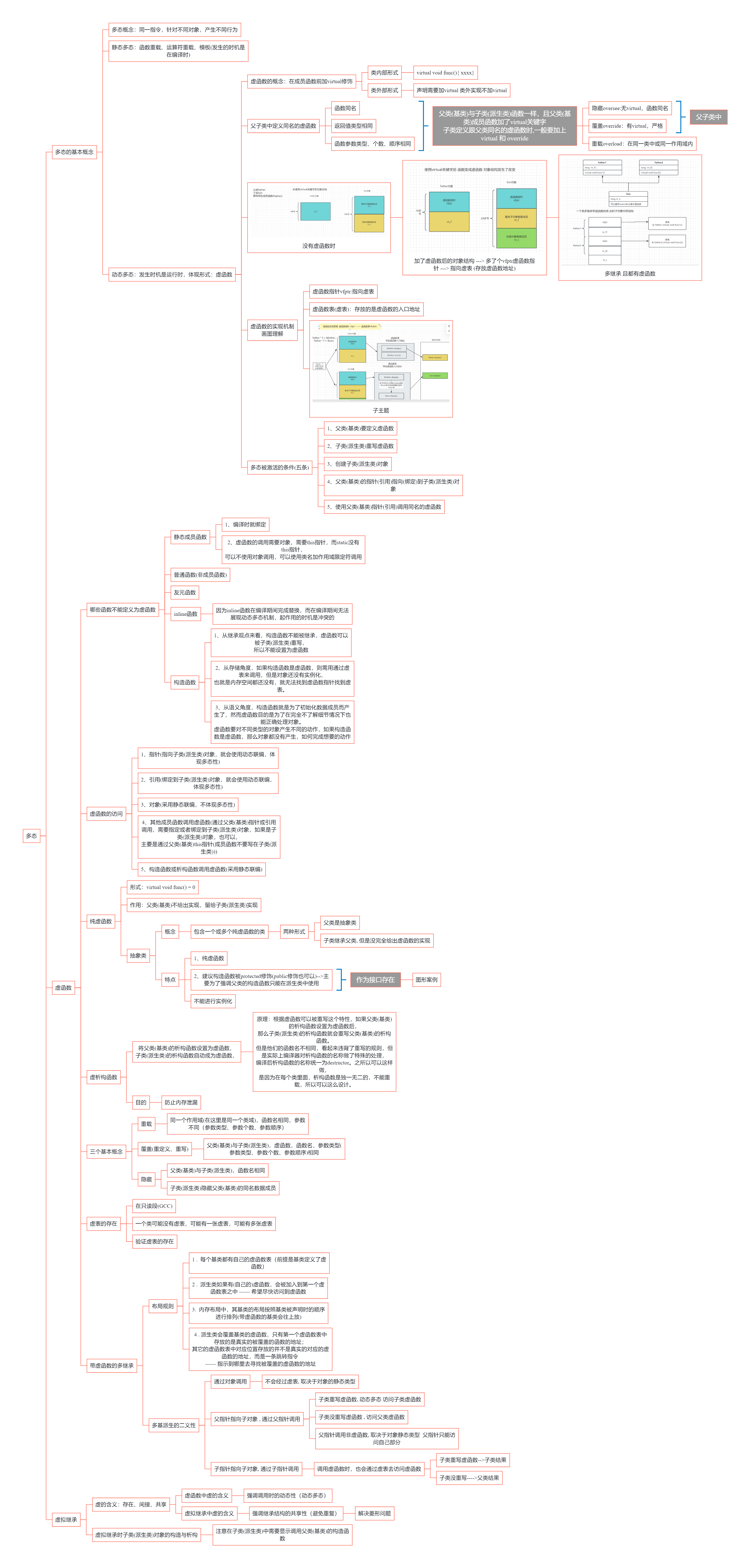
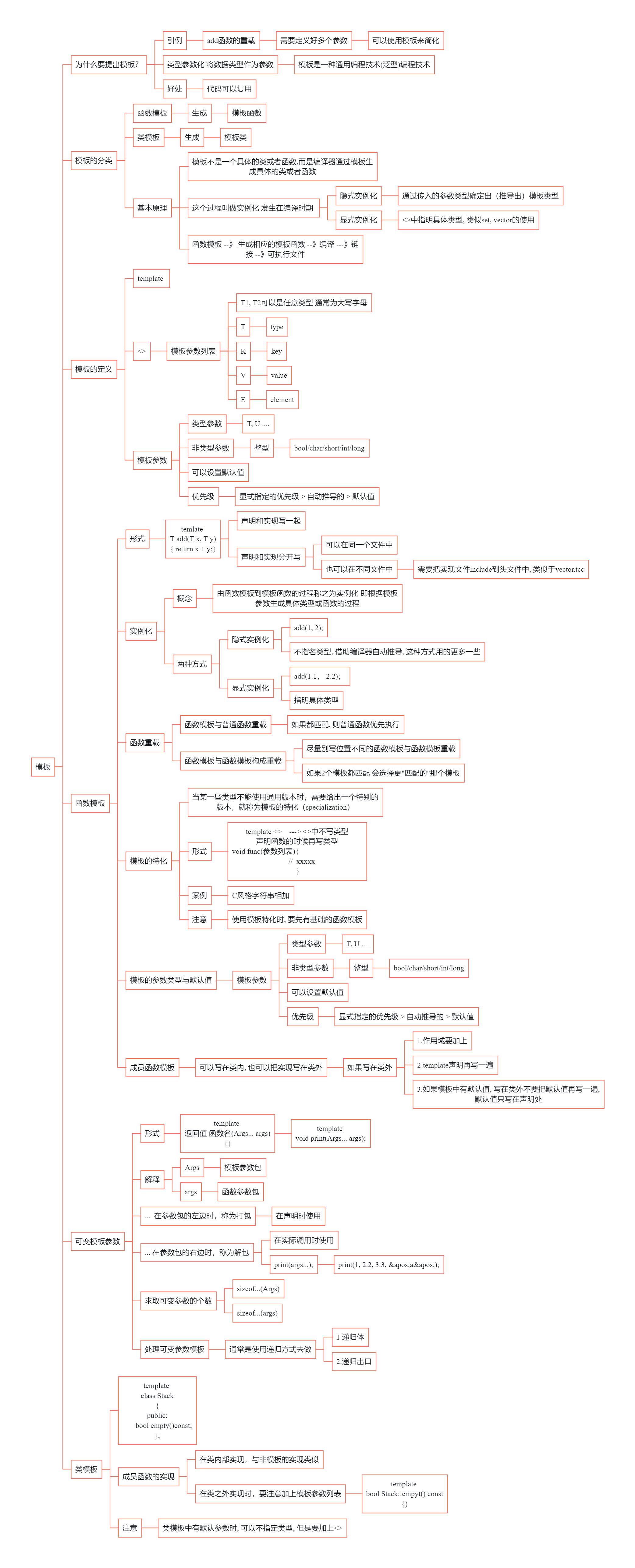
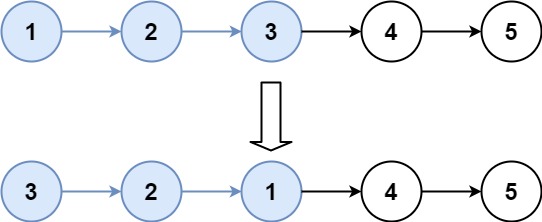
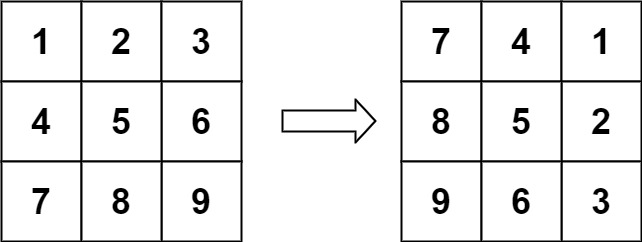
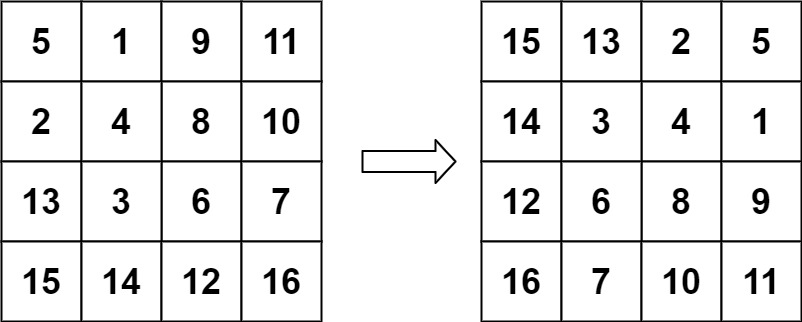
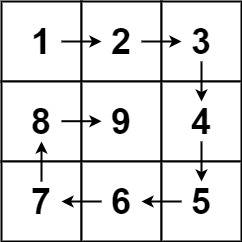
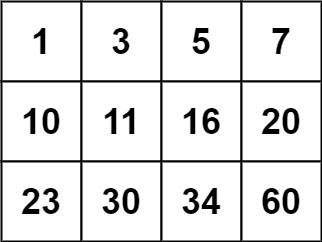
儿时父问偏爱处,低语轻藏一段真。
当日随言风过耳,而今方觉是长春。
有一读:《道德经》第九章
一、原文
持而盈之,不如其已;揣而锐之,不可长保。金玉满堂,莫之能守;富贵而骄,自遗其咎。功遂身退,天之道也。
二、解读
1.四句话对应四层天道:
持盈:物质欲望满→溢损;
揣锐:才华锋芒满→摧折;
满堂:财富占有满→散失;
骄奢:地位心气满→灾咎。
结论:满是衰败临界点,知止就是合道。
功成身退不是归隐避世,是收敛占有欲、放下居功之心,不霸占功名成果,效法天地四时功成不居。是价值观的退守,不是人生的退场。
2.本章总纲
本章是老子反极端、守中道、物极必反辩证思想的纲领篇,贯通全书"大成若缺、大盈若冲"(四十五章)内核。自然规律(盈必亏)→四种人性弊病(贪盈、逞锐、囤财、骄奢)→祸患结局→终极解法(功成身退、顺应天道)承接第八章水德处下不争,从"处世不争"细化为"行事知止戒满",是由天道到做人做事的实操准则。
有一读:《道德经》第八章
《道德经》第八章・原文
上善若水。水善利万物而不争,处众人之所恶,故几于道。居善地,心善渊,与善仁,言善信,正善治,事善能,动善时。夫唯不争,故无尤。
一、总注:上善之人,如水之性
上善 = 最高级的生命范式,不只狭义道德善良:老子用水象征道的三大属性:柔、处卑、利物不争,是道家理想人格标准,区别儒家"崇德尚刚、积极进取"的君子观。
利万物不争:水施润泽,养育生灵,不自矜功德。
处众人之所恶:人喜高处尊位,水独趋低洼污下之地。
不争非躺平避世,水居低位,汇聚百川,柔弱蓄势、以谦成大;世人争抢显贵,反被名利束缚,水守众人所恶,反得万物依附。
七善是动态处世:居择低处避祸、心藏深渊戒躁、待人存赤子之仁、言语守本心之信、为政持平如水、处事扬长避短、行动择机而动,七善归一,落脚"不争"。不争是柔性竞争,不是放弃成长。以退让、利他、处下的方式,实现长久保全,是辩证处世智慧;不争是全本道德经核心方法论。
七善是全方位人生修养纲目:立身、心性、交友、言语、理政、办事、行动七大维度的行为准则;七善是效法水德的落地细则,由身到家、由家到治国。从自然物象上升本体论打通"道 — 德 — 人事"逻辑。
夫唯不争故无尤:不争私利、不结争端,自然远离灾祸过失,是全章落脚点。
二、全章逻辑总结
总纲:上善若水(以水喻道、立人格标杆)→三大水德(利物、不争、处下→几于道)→七善细则(从身心到行事全套修炼)→结论(不争→无过失无祸患)全章以自然物象打通天道→人道→治道,是《道德经》从形而上落地世俗实践最重要的篇目。
有一读:《道德经》第七章
原文:天长地久。天地所以能长且久者,以其不自生,故能长生。是以圣人后其身而身先,外其身而身存。非以其无私邪?故能成其私。
一、字词核心释义
不自生:本章核心。并非"不生存",而是无自私的目的、不刻意为己谋利、不与万物相争,纯任自然运化。
后其身 / 外其身:处世姿态。谦退居后、置己身于利害之外,放下小我计较。
无私→成其私:辩证关系。前"私"指私欲、私心;后"私"指生命价值、立身之本、长久归宿,二者内涵完全不同。
本章由天道推人事,建立"利他 = 长久,无私 = 大成"的宇宙人生法则:天地"不自生":破除自我中心,顺应大道,故永恒。圣人"后身、外身":放下小我私欲,服务众人,反而获得真正的立身与影响力。"成其私":成就的不是一己私欲,而是人格、事业、生命价值的圆满。
二、本章核心哲学:三大辩证智慧
1. 有我→无我:长久的根本
人往往"为己而生",追逐名利、守护自我,反而患得患失、难以长久。天地"不自生"=无我,不把自我当作中心,全心运化万物,反而获得永恒。结论:执着小我,是烦恼与短暂的根源;放下小我,是长久与安宁的起点。
2. 争先→退后:处世的法则
世俗逻辑:争先、占有、凸显自我,才能得利。老子天道逻辑:后其身、外其身、谦退让人,众人自然推你向前。这不是消极退让,而是顺势而为、以退为进的高级生存智慧。
3. 无私→成私:公私的终极统一
俗人之私:私欲、占有、利己,越小气,越失去;
圣人之无私:舍己、利他、为公,越无私,越能成就大私(生命价值、事业、民心、立身)。
三、全章主旨总结
《道德经》第七章以天地为喻,揭示贯穿全书的核心法则:道法自然,去私忘我;谦退不争,利他利己。天地因"不为自己"而永恒,圣人因"放下自我"而大成。无私,不是牺牲自我,而是成就真正、长久的自我。
把本章总结为三层境界:
天道层:天地无心无私,所以天长地久;
人格层:圣人谦退忘我,所以受人尊崇、保全自身;
人生层:越计较得失,越容易失去;越放下自我,越能成就自我。
有一读:《道德经》第六章 —— 《道德经・第六章》深度名家拓展解读
1.原文:谷神不死,是谓玄牝。玄牝之门,是为天地根。绵绵若存,用之不勤。
有形万物皆有生灭:草木枯荣、山河变迁、星体成坏,唯独虚空大道(谷神)永恒不变,这种永恒不息的生化本体,就取名「玄牝」。玄为天,牝为地,玄牝是天地生化的母体,类比母体生育,天地万物皆从此生出;玄牝不是具象器物、不是实体母体,是大道化生万物的功能枢机,无形之门,是有形天地万物赖以生成的总根源。细微绵长、连绵不绝,看不见形体,却时时刻刻在起作用,大道生发万物,取用无穷、永不枯竭。勤:古训为「竭尽、穷尽」(非勤劳,古文字考据:勤 = 匮竭)。
2.三大主流学术流派拓展深度延伸
(一)魏晋玄学派(王弼为代表:哲学本体论)
本章确立老子「无本论」:有形 = 有,有必有穷尽;虚空 = 无,无方能永续。谷神(无)是本体,玄牝是无化生有的功能;整个玄学体系:天地万物生于无,依托于无,第六章是王弼《老子注》立论根基,直接影响魏晋哲学、玄学思潮。
(二)黄老道家 / 道教内丹派(河上公、葛洪、全真道:生命修炼学)
外天地,内人身:天地有玄牝生万物,人身有玄牝生元气,修行核心便是守谷神之虚、养玄牝元气;道教把本章奉为丹道源头经文:「谷神守空、玄牝固元」,恬淡虚静、少耗精气神,即可如谷神不死,实现养生长生,深刻影响中医养生、传统导引术。
(三)现代哲学与思想史(冯友兰、陈鼓应:先秦宇宙哲学)
破除创世神观念:先秦商周普遍信奉天帝创世,老子首次以「虚空大道自然生化」解释宇宙起源,是中国哲学从神本走向人本、自然本的关键;辩证思想:虚与实、无形与有形、本源与万象的辩证统一:空(谷)为体,生(玄牝)为用,体空用无穷。
3.总结全章主旨(汇总各家定论)
第六章全文一句话总纲:虚空的大道本体永恒不灭,这个造化万物的幽深本源叫玄牝;大道生化的枢机,便是天地万物的总根源;它连绵幽微、似有若无,造化万物的功用无穷无尽、永不枯竭。老子借天地生化,既建立道为宇宙本源的本体哲学,又暗藏修身虚静、效法天道的人生智慧,是《道德经》「道体论」最短却最核心的一章。
有一读:《道德经》第五章深度延展解读
《道德经》第五章是老子世界观与处世哲学的核心篇章,跳出了世俗善恶、偏爱、干预的执念,搭建起一套顺应天道、安守本心、无为自化的顶级生命智慧。全文以天地大道为喻,从宇宙规律落到人间处世,破除世人偏执、妄为、多言的弊病,为众生应对纷繁世事、百态人生提供了根本准则。
一、天地不仁,以万物为刍狗;圣人不仁,以百姓为刍狗:破除分别心,方是最大的公正
世人对"仁"的世俗认知,往往是偏爱、偏袒、慈悲式的区别对待:偏爱美好、厌恶丑恶,亲近顺遂、排斥坎坷,优待良善、摒弃参差。但老子笔下的天地之仁、圣人之仁,是无分别的至公,而非世俗的私情。
所谓"刍狗",是古代祭祀用的草扎之狗。祭祀之时,人们尊之敬之、陈设供奉;祭祀结束,便弃之荒野、任其自然,不刻意珍视,也不刻意践踏。这并非冷漠无情,而是顺其自然、不加干预、不生执念的终极公平。
天地从无世俗的好恶偏见:暖阳不独照繁花似锦的佳木,亦普照荆棘毒草;甘霖不独滋养良田沃土,亦润泽荒漠杂草;四季轮转,不因人的喜好而永驻春夏,不因万物的凋零而停滞更迭。万物的兴衰、生灭、枯荣,皆遵循自身天性与天道规律,天地不偏爱、不干预、不掌控,不刻意成全,也不刻意惩罚。
推及人间,"圣人不仁,以百姓为刍狗",是悟道者的治国、处世本心。真正的智者、仁者、上位者,摒弃个人私情与主观偏好,不对世人区别对待。不偏爱富贵、不轻视平凡,不偏袒聪慧、不鄙夷愚钝,不强行改造他人的人生,不刻意干涉众生的活法。
世俗最大的痛苦,皆源于分别心:我们执着于好坏、得失、美丑、顺逆,希望万事如己所愿,强求美好长存、祸患远离。而老子告诉我们,天道的本质是包容一切存在,接纳一切状态。允许万物各有其性,允许众生各有其命,接纳世事的参差百态,放下执念与干预,便是顺应天道的第一步。
二、天地之间,其犹橐龠乎?虚而不屈,动而愈出:虚空生万物,流动方永恒
老子以古代冶铁的橐龠(风箱)喻天地宇宙,道破了宇宙运行的核心秘密:虚空是万物生发的本源,动态循环是天地永恒的规律。
风箱的核心价值,在于"空"。中空无物,所以不会穷尽、不会枯竭,便是"虚而不屈"。它没有固定的形态、没有固化的执念、没有填满的私欲,正因极致的虚空,才拥有无限的包容力与生命力。世人之所以困顿、枯竭、内耗,本质是内心被欲望、偏见、执念、杂念填满,心满则滞、心塞则穷,再也容纳不下新生与变化。
而"动而愈出",揭示了宇宙的动态本质:天地从未静止,四时轮转、万物生灭、人事更迭,始终处于动态循环之中。风箱鼓动不息,生生之风便源源不断;天地运化不止,世间万象便生生不息。春生、夏长、秋收、冬藏,花开叶落、缘聚缘散、新旧交替,没有永恒的圆满,也没有极致的绝境,所有变化都是天道自然的运化。
这一句破除了世人"求稳、求恒、求不变"的执念。人间万事,唯一的永恒就是变化。众生痛苦的根源,就是妄图用固化的认知、偏执的欲望,去锁住瞬息万变的世界。殊不知,虚空方能承载万物,流动方能生生不息。人生亦是如此,唯有保持内心的空明通透,清空杂念、放下固有认知、舍弃过度掌控,才能在世事变动中生生不息、从容自在。
三、多言数穷,不如守中:寡欲少妄,守中持正,是处世根本
"多言数穷",从来不是单纯指"话多必失",而是广义上的妄言、妄论、妄为、过度干预、过度思虑。
结合前文的天地大道,世间万物本自具足、自化自成,有其固有规律。世人却总爱自作聪明:随意评判是非、肆意干预他人、强行掌控事态、过度思虑内耗、喋喋不休说教干涉。越是执着言说、强行改变、刻意掌控,就越容易打破自然平衡,制造矛盾与困扰,最终走入山穷水尽的困境,这便是"数穷"。
生活中所有的内耗、焦虑、纷争、遗憾,皆源于"多言多妄":对他人的人生指手画脚,对既定的世事耿耿于怀,对无法掌控的结果反复纠结,用主观执念对抗客观规律,最终只会徒劳无功、身心俱疲。而老子给出的终极解法,便是不如守中。
"守中"是儒释道三家共通的最高智慧,却各有侧重、内核归一,是贯穿中国传统文化的处世正道:
儒家之中,是中庸有度:不偏不倚、不走极端,待人处事谦和适度,进退有度、刚柔并济,不偏执、不激进、不盲从,恪守人情事理的中正之道;
佛家之中,是离相无执:不执着于苦乐、得失、善恶的表象,不沉溺欢喜、不沉沦痛苦,放下执念、心如止水,安住本心;
道家之中,是虚静守一:守住内心的虚空清明、宁静纯粹,不妄为、不贪求、不躁动,顺应天道规律,不强行干预万物与世事。
老子所言的"守中",本质是守住本心的静定,守住万物的自然。对外,尊重万物规律,接纳世事变化,不评判、不干预、不强求;对内,清空杂念私欲,保持内心空明,不躁动、不内耗、不偏执。
四、全章核心终极内核:顺其自然,守中安己,无为无不为
第五章通篇层层递进,构建了完整的人生修行体系:先以天地立心,教我们破除分别心,接纳世间百态,看懂天道至公、万物自然;再以橐龠悟道,教我们放空自我执念,接纳世事流变,明白虚空生万物、变动是常态;最后以守中收尾,教我们收敛妄为、安守本心,以静定之心应对万千纷扰。
真正的"无为",从来不是消极躺平、无所作为,而是不妄为、不强为、不逆道而为。
做人,学天地之公,包容参差、接纳不完美,允许花开花落、人来人往,不执是非、不困得失;修心,学橐龠之虚,清空执念、保持通透,让内心有余地、生命有生机;处世,守中道之正,少言少妄、少扰少执,顺势而为、静待自成。
世间最好的活法,便是:对外顺应万物,不干预、不强求;对内坚守本心,不躁动、不迷茫。以无我之心观万象,以守中之道渡余生。
有一读:《道德经》第五章
《道德经》第五章深度延展解读
《道德经》第五章是老子世界观与处世哲学的核心篇章,跳出了世俗善恶、偏爱、干预的执念,搭建起一套顺应天道、安守本心、无为自化的顶级生命智慧。全文以天地大道为喻,从宇宙规律落到人间处世,破除世人偏执、妄为、多言的弊病,为众生应对纷繁世事、百态人生提供了根本准则。
一、天地不仁,以万物为刍狗;圣人不仁,以百姓为刍狗:破除分别心,方是最大的公正
世人对"仁"的世俗认知,往往是偏爱、偏袒、慈悲式的区别对待:偏爱美好、厌恶丑恶,亲近顺遂、排斥坎坷,优待良善、摒弃参差。但老子笔下的天地之仁、圣人之仁,是无分别的至公,而非世俗的私情。
所谓"刍狗",是古代祭祀用的草扎之狗。祭祀之时,人们尊之敬之、陈设供奉;祭祀结束,便弃之荒野、任其自然,不刻意珍视,也不刻意践踏。这并非冷漠无情,而是顺其自然、不加干预、不生执念的终极公平。
天地从无世俗的好恶偏见:暖阳不独照繁花似锦的佳木,亦普照荆棘毒草;甘霖不独滋养良田沃土,亦润泽荒漠杂草;四季轮转,不因人的喜好而永驻春夏,不因万物的凋零而停滞更迭。万物的兴衰、生灭、枯荣,皆遵循自身天性与天道规律,天地不偏爱、不干预、不掌控,不刻意成全,也不刻意惩罚。
推及人间,"圣人不仁,以百姓为刍狗",是悟道者的治国、处世本心。真正的智者、仁者、上位者,摒弃个人私情与主观偏好,不对世人区别对待。不偏爱富贵、不轻视平凡,不偏袒聪慧、不鄙夷愚钝,不强行改造他人的人生,不刻意干涉众生的活法。
世俗最大的痛苦,皆源于分别心:我们执着于好坏、得失、美丑、顺逆,希望万事如己所愿,强求美好长存、祸患远离。而老子告诉我们,天道的本质是包容一切存在,接纳一切状态。允许万物各有其性,允许众生各有其命,接纳世事的参差百态,放下执念与干预,便是顺应天道的第一步。
二、天地之间,其犹橐龠乎?虚而不屈,动而愈出:虚空生万物,流动方永恒
老子以古代冶铁的橐龠(风箱)喻天地宇宙,道破了宇宙运行的核心秘密:虚空是万物生发的本源,动态循环是天地永恒的规律。
风箱的核心价值,在于"空"。中空无物,所以不会穷尽、不会枯竭,便是"虚而不屈"。它没有固定的形态、没有固化的执念、没有填满的私欲,正因极致的虚空,才拥有无限的包容力与生命力。世人之所以困顿、枯竭、内耗,本质是内心被欲望、偏见、执念、杂念填满,心满则滞、心塞则穷,再也容纳不下新生与变化。
而"动而愈出",揭示了宇宙的动态本质:天地从未静止,四时轮转、万物生灭、人事更迭,始终处于动态循环之中。风箱鼓动不息,生生之风便源源不断;天地运化不止,世间万象便生生不息。春生、夏长、秋收、冬藏,花开叶落、缘聚缘散、新旧交替,没有永恒的圆满,也没有极致的绝境,所有变化都是天道自然的运化。
这一句破除了世人"求稳、求恒、求不变"的执念。人间万事,唯一的永恒就是变化。众生痛苦的根源,就是妄图用固化的认知、偏执的欲望,去锁住瞬息万变的世界。殊不知,虚空方能承载万物,流动方能生生不息。人生亦是如此,唯有保持内心的空明通透,清空杂念、放下固有认知、舍弃过度掌控,才能在世事变动中生生不息、从容自在。
三、多言数穷,不如守中:寡欲少妄,守中持正,是处世根本
"多言数穷",从来不是单纯指"话多必失",而是广义上的妄言、妄论、妄为、过度干预、过度思虑。
结合前文的天地大道,世间万物本自具足、自化自成,有其固有规律。世人却总爱自作聪明:随意评判是非、肆意干预他人、强行掌控事态、过度思虑内耗、喋喋不休说教干涉。越是执着言说、强行改变、刻意掌控,就越容易打破自然平衡,制造矛盾与困扰,最终走入山穷水尽的困境,这便是"数穷"。
生活中所有的内耗、焦虑、纷争、遗憾,皆源于"多言多妄":对他人的人生指手画脚,对既定的世事耿耿于怀,对无法掌控的结果反复纠结,用主观执念对抗客观规律,最终只会徒劳无功、身心俱疲。而老子给出的终极解法,便是不如守中。
"守中"是儒释道三家共通的最高智慧,却各有侧重、内核归一,是贯穿中国传统文化的处世正道:
儒家之中,是中庸有度:不偏不倚、不走极端,待人处事谦和适度,进退有度、刚柔并济,不偏执、不激进、不盲从,恪守人情事理的中正之道;
佛家之中,是离相无执:不执着于苦乐、得失、善恶的表象,不沉溺欢喜、不沉沦痛苦,放下执念、心如止水,安住本心;
道家之中,是虚静守一:守住内心的虚空清明、宁静纯粹,不妄为、不贪求、不躁动,顺应天道规律,不强行干预万物与世事。
老子所言的"守中",本质是守住本心的静定,守住万物的自然。对外,尊重万物规律,接纳世事变化,不评判、不干预、不强求;对内,清空杂念私欲,保持内心空明,不躁动、不内耗、不偏执。
四、全章核心终极内核:顺其自然,守中安己,无为无不为
第五章通篇层层递进,构建了完整的人生修行体系:先以天地立心,教我们破除分别心,接纳世间百态,看懂天道至公、万物自然;再以橐龠悟道,教我们放空自我执念,接纳世事流变,明白虚空生万物、变动是常态;最后以守中收尾,教我们收敛妄为、安守本心,以静定之心应对万千纷扰。
真正的"无为",从来不是消极躺平、无所作为,而是不妄为、不强为、不逆道而为。
做人,学天地之公,包容参差、接纳不完美,允许花开花落、人来人往,不执是非、不困得失;修心,学橐龠之虚,清空执念、保持通透,让内心有余地、生命有生机;处世,守中道之正,少言少妄、少扰少执,顺势而为、静待自成。
世间最好的活法,便是:对外顺应万物,不干预、不强求;对内坚守本心,不躁动、不迷茫。以无我之心观万象,以守中之道渡余生。
有一读:《道德经》第四章 —— 《道德经》第四章深度延展解读
《道德经》第四章:道冲而用之或不盈。渊兮似万物之宗。挫其锐,解其纷,和其光,同其尘。湛兮似或存。吾不知谁之子,象帝之先。
这一章,是老子亲口向尹喜直观描述证道境界,是整部《道德经》最核心、最究竟、最直接的"道体样貌"。前面三章讲"人心治理、社会治理、欲望治理",第四章直接跳至宇宙本源、生命本体、大道本体,从外在修身治国,进入究竟悟道。
一、道冲而用之或不盈:虚空为体,无穷为用
道虽是虚空,却具足无穷活力,万物离不开它。
【深度延展】世人最大误区:认为"空"就是没有、虚无、无用。老子所说的"冲",是中空、虚灵、不含执念、不含固化、不含局限的状态。
正因为道彻底为空、不占位、不自满、不张扬,所以它的作用永远不会枯竭。万物有形皆有尽,水杯满则溢、月亮圆则缺、人盛极必衰。唯独大道,以空为体,以用为显,越用越生、生生不息、永不盈满。
人生修行同理:心中越不空、执念越多、欲望越满,人生越枯竭。内心越虚空、放下越多、清空越多,生命力越源源不断。
二、渊兮似万物之宗:深不可测,万有之根
道深不见底、幽远无尽,是万物最初的源头、万物之母、万象之根。
【深度延展】看得见的世界是"果",看不见的大道是"根"。山川河流、日月星辰、春夏秋冬、生死兴衰,全部从这一份幽深本体中流淌而出。
普通人只看世界表象,修道人直取万物本源。所有变化、所有规律、所有生命逻辑,皆源于此"渊"。越深、越静、越看不见,力量越宏大。
三、挫其锐:收敛锋芒,炉火纯青,是修行第一关口
道不锋芒毕露,藏于万物。修道磨平锐气,归于恬淡博大,如炉火纯青。
【深度延展】什么是真正的锐气?争强、好胜、张扬、炫耀、争辩、不服、傲慢、显能、争先。
凡人以锐为荣,处处表现、处处争先、处处彰显自我;大道以锐为病,所以自挫其锐。
炉火比喻极其精妙:刚开始燃烧,浓烟滚滚、火光冲天、声势浩大,是躁动之火;修行到深处,火光内敛、温厚温润、看似无为、实则能量纯足,是纯青之火。
锋芒外露是消耗,内敛藏光是滋养。所有真正的高人、大道、大德,全部都是:不显、不露、不争、不亮。
四、解其纷:化解繁杂,随顺变化,安住当下
道化解万象纷扰,让万物有序生长。智者随顺变化,安住当下。
【深度延展】世间最大的痛苦,来自人心纷乱、执念纷乱、得失纷乱、情绪纷乱。外在世界本无对错、本无纷争,纷乱全部来自人的分别与执着。
"解其纷"有两层深意:
道能解天地之纷:四季更迭、万物枯荣、风雨阴晴,看似杂乱,实则井然有序,大道默默调和一切矛盾。
人能解自心之纷:修行不是改变世界,而是解开自己内心的纠缠、纠结、执念、不甘、妄想。
万物时刻在变,没有永恒的状态。看懂变化、接纳变化、顺应变化,就是最高智慧。不与时代对抗、不与境遇对抗、不与无常对抗,心安即是归处。
五、和其光,同其尘:最高级的通透,不是清高,是圆融
和光同尘不是随波逐流,是主动选择与世无争、不露锋芒。
【深度延展】这是整部道德经最被误解、最高境界的修行。
很多人以为:修道就要清高、孤僻、远离人间、不染凡尘。老子恰恰相反:真正的道,可在光明中璀璨,可在尘埃中安然。
遇光明,不嫉妒、不疏离、融入光明;遇污浊,不傲慢、不排斥、接纳尘埃。
和光同尘,是同流而不合污,入世而不世俗。外表和普通人一样,过日子、做事情、处众生;内心清净通透、无争无执、自在逍遥。
清高是小我,同尘是大我。独处容易,混迹人群不染心最难。
六、湛兮似或存:非空非有,虚实不二
道湛然清净、深远寂寥,似有似无、无形无相。
【深度延展】眼睛看不见、耳朵听不见、身体摸不到,却时刻发挥作用。空气看不见,人离不开;规律看不见,万物遵循;大道看不见,生死兴衰皆由它主宰。
似存似无,是宇宙最高真相。有形之物终会毁灭,无形大道永恒长存。
七、吾不知谁之子,象帝之先:大道无始无终,万法本源
道在天地神明之前就存在,无人创造大道,大道自生自有。
【深度延展】世间一切皆有源头:树木有种子、江河有源头、天地有运化。唯独大道无始、无终、无父、无母、无创造者。
它不是被谁制造出来的,它是一切存在的前提。
这彻底打破了"神创、天创、主宰创"的认知:大道不是产物,大道是本源。
八、整章总括:道的五大特质(核心总结)
体虚空,用无穷——不盈不竭,生生不息
性幽深,为宗主——万物根源,究竟本源
态内敛,不张扬——挫锐藏锋,炉火纯青
能调和,解纷乱——顺变安住,井然自在
相无形,超时空——非空非有,先于天地
九、落地修行启示:为何修道之人多甘于平凡
正因为道无处不在、不露锋芒、隐于平凡:
大道不在深山,不在庙宇,就在日常一言一行、一饭一蔬、一动一静,皆是道。
真正修道,不做名人、不做强势、不做张扬之人。大人物多锋芒、多纷争、多消耗;修道人守平凡、守清净、守本分。
不显、不争、不炫、不躁、不纷、不染。看似普通,实则圆满;看似无为,实则全道。
最终达到:心虚空、性恬淡、身安然、行自在、与世同尘、与道同频。
有一读:《道德经》第三章 —— 《道德经》"不尚贤" 章解读延展
一、原文本义:为政的底层逻辑
"不尚贤,使民不争;不贵难得之货,使民不为盗;不见可欲,使民心不乱",是老子无为而治的核心施政理念。老子所处的春秋乱世,诸侯竞相标榜贤能、追逐奇珍、放纵贪欲,社会攀比、倾轧、乱象丛生。他并非否定贤才、否定财物,而是反对刻意标榜、人为拔高:人为树立 "贤" 的标准,就会催生沽名钓誉、争名夺利;刻意抬高稀有之物的价值,就会诱发贪念与窃盗;主动展示奢靡、诱惑人心的事物,便会让民众心神躁动、失其本真。这三句本质是去外在妄念,归人心本静:外在的价值导向,是扰乱人心、制造纷争的根源。老子主张统治者减少人为的诱导与刻意的褒扬,让社会回归自然常态。
二、由政入心:从治理天下到安顿自我
经文由治国转向修身:是以圣人之治,虚其心,实其腹,弱其志,强其骨。这十六字,是道家修身的总纲,也是性命双修,分两层拆解:
虚其心,弱其志 —— 性功(修心、修性) "虚其心",是清空杂念、贪欲、分别心、执念、嗔痴等外在侵扰,让内心空明澄澈,不被外物裹挟。佛家念佛、参禅,道家守静、观心,归根结底都是涤荡妄念。 "弱其志" 并非消磨志向、浑浑噩噩,而是弱化向外攀求、攀比、争竞的执念之志。放下对功名、财富、虚名的过度追逐,不被世俗欲望牵着走,守住本心。二者相合,便是修心性、开智慧,对应道家 "性功"。
实其腹,强其骨 —— 命功(养身、养命) 表层含义很朴素:安于温饱,滋养身体。从道家修行角度,"实其腹" 引申为涵养精气神,守住生命本源(丹田元气),让内在能量充盈;"强其骨" 即强健体魄、固本培元。这便是养护肉身与生命根基的 "命功"。
道家 "只修性,不修命,万劫阴灵难入圣;只修命,不修性,恰似煮砂难成金",正印证了二者不可偏废:心性通透而身体衰朽,难长久;体魄强健而心神迷乱,亦非正道,性命合一,才是完整的修行。
三、天人合一:修身与处世的贯通
"人身小宇宙,天人合一",是中华传统文化共通的内核,儒、道、释皆有呼应:道家认为个体生命与天地大道同频,人心的秩序,对应家国天下的秩序。一个人若能做到心无妄念、身心康泰,懂得克制贪欲、不争不抢,这份定力与智慧,便可延伸到持家、处事、理政。佛家 "芥子纳须弥",也是说微小的个体之内,藏着世间万象,修己便是修万物。
老子的智慧从不是脱离现实的出世玄学:治理天下,先治理人心;安顿他人,先修好自身。外在的纷争、浮躁、贪婪,根源永远在人心。放下世俗强加的价值标准,不困于攀比、不迷于物欲、不乱于诱惑,对内清空杂念、滋养身心,对外顺势而为、不刻意造作,便是读懂这一章的核心。
四、当代现实启示
放在当下,这段文字依然极具现实意义:如今社会推崇财富、流量、名望,各类 "标准" 不断制造焦虑,攀比之心、浮躁之气随处可见。"不尚贤、不贵货、不见可欲",并非拒绝努力、拒绝美好,而是不被单一的世俗价值绑架。 "虚其心" 是学会断舍离,放下不必要的焦虑与执念;"实其腹、强其骨" 是关照健康、夯实生活根本;"弱其志" 是减少无谓的内耗与争斗。人这一生,外在的名利财物皆是过眼云烟,内心的安宁、身心的康健、与大道相融的自在,才是让生命真正饱满的本源快乐。
整体而言,将经文从政治理念,延伸到心性修行、性命双修,再落脚到生命价值的思考,层层递进,精准抓住了《道德经》"内圣外王" 的核心精髓。
与子书:在潮汕地区一直流传着:借人一根钉,需还一根梁的老话。看似是多还了几倍的人情,实则藏着最通透的处世智慧。因为人情往来,从不止是一笔经济账,你占的每一点小便宜,省下的每一点小利,背后都在悄悄积攒着别人的不满与怨气。《道德经》有云:既以为人,己愈有。既以与人,既愈多。你看似傻傻的付出,其实都是在为自己积福、铺路、攒人脉。你付出的善意、帮过的人、让过的利,就像撒在土里的种子,会悄悄地生根发芽,最终会带给你加倍的回报。那些心底厚道,从不占便宜的人,福气和好运往往不请自来。人这一生,厚道不吃亏,善良有回响,让利者天必助之。
与子书:宇宙第一法则便是付出,生命的第一需求就是给予。当人愿意主动向外布施付出,人生自会走向丰盈富足;若是始终习惯向外求索、一味执念索取,人生终究会陷入内心与物质的双重匮乏。怀揣欢喜本心踏实行事,秉持利他之心主动付出,是积攒福报与财富的根基。世间常态向来如此,越是吝啬不愿付出的人,往往生活困顿;甘愿持续付出的人,反倒愈发富足顺遂。这也是世上富人寥寥、穷人居多的根源:世间大多人都想着获取占有,真正愿意真心给予的人却寥寥无几。财富本身便是自身能量的外在显现,想要提升自身能量修为,恪守十二字:正大光明,积极向上,乐于助人。
与子书:儒释道经典讲透了人生必须处理的三种关系:人与人的关系、人与自己的关系、人与世间规律的关系。
1.儒家:修处世立身,理顺人与人的关系。儒家着眼于俗世人情,讲究入世做人,定下了人际交往的行事准则。秉持着"己所不欲,勿施于人"的处世本心,以信为做人底线,守信方能让人安心相交;以义为处事格局,明道义方能心胸坦荡;以仁为相处温度,怀仁心方能善待旁人。守住这三把标尺,待人真诚有度,相处坦荡靠谱,自然而然能收获他人信赖。这份沉淀下来的信任,便是行走世间最安稳的底气,也是立足红尘的根本。儒家本质,便是教会人如何堂堂正正立身于世,修好世间人情。
2.佛家:修本心心境,和解人与自己的关系。佛家向内求索,探究内心本源,解决人内心的困顿与内耗。正如《六祖坛经》所言"菩提本无树,明镜亦非台",世间大多烦恼,从来都不是外物带来,而是源于自身生出的执念。执念是困住自身的心魔,得失放不下、过往忘不了、心事解不开,便会终日被情绪裹挟。所谓放下,从来不是轻言放弃生活,而是抛开纠缠自己的杂念妄念。当内心得以安顿平和,便会发觉周遭纷扰都会随之淡去。佛家修的是本心,学会安抚心绪,接纳自我,做到内心从容安宁。
3.道家:修顺势知命,洞悉人与规律的关系。道家放眼天地万物,参悟自然法则,通晓人与天道规律的相处之道。世间万事自有章法,春种秋收顺时节而行,盛极必衰懂物极必反,万事皆有定数。人之所以活得疲惫煎熬,大多是强行逆势而为,强求不属于自己的人和事。奉行"人法地,地法天,天法道,道法自然",认清规律、顺应趋势,不逆势较劲,不盲目强求。通晓道家智慧,便如同手握人生导航,知晓何时进、何时退。道家便是教人认清天命大势,找准人生前行的道路。
4.儒家教你立身,把人做好;佛家教你立心,把心安好;道家教你立命,把路走好。真正活的通透之人,向来是身在红尘历练本心,遵循规律打磨自身品性,顺应自然窥见本真性情。修行从不是苛求改变外界,也不是挑拣他人过错,而是向内自省,雕琢自身品性,改掉自身弊病。唯有不断精进自我,方能处事从容,心安路稳。
与子书:圣严法师说:心里放不下自己,那是没有智慧;心里容不下别人,那是没有慈悲。所以我们既要知道别人,更要知道自己;既要战胜别人,又要战胜自己;既要宽容自己,更要容下别人。☕
与子书:90%人走偏,不是智商差、不是家境穷,是4个核心成长底线,没管住、没守牢。一是管住“懒散”,是毁掉人的“慢性毒药”,养出刻进骨子里的自律,成长第一步。彻底根治懒散,规矩一:今日事今日毕,绝不拖延;规矩二:早睡早起,作息绝不乱;规矩三:做事有计划,不盲目瞎忙。二是管住“欲望”,放纵欲望,是一个人成才的“最大陷阱”;学会延迟满足,才能扛住诱惑。三是管住“脾气”,坏脾气,是人人生的“最大绊脚石”,修炼好性格,决定人一生上限。四是管住“规矩”,无规矩,不成才,没底线,必毁人;守住底线规矩,人才能走正道。
与子书:人这一生,说话最见人品与格局。脾气人人都有,克制才是本事。言语温柔,不是软弱,而是通透。别用恶语伤人,人情薄如一张纸。生活大半烦恼,都源于口无遮拦。少抱怨少指责,懂得换位思考。管住嘴,稳住心,日子才会顺遂。好好待人,好好言语,善待身边人。不争口舌输赢,方能少结人间恩怨。心宽言缓,处事有度,便是大智慧。嘴下留德,心存善念,万事皆会圆满。
与子书:人的福报不是求来的,而是修来的。福从哪里修呢?
第一条:从善良里修,善良是立身的根本,根基扎得正,福报的枝叶才会自然舒展,一个人如果失了善良的底色,再怎么向外追逐得到的都是沙上建塔终究成空。
第二条:从知足里修,古人说;良田万顷不过一日三餐,广厦万间只睡卧榻三尺,真正的富足从不在外在的堆砌,而在内心的充盈。知足者能在寻常烟火中品出甘甜,而贪心者,却在无尽欲求里备受煎熬,这便是福与苦的分水岭。
第三条:从感恩里修,心怀感恩的人自会吸引世间的美好向自己汇聚,福报便会在这份真诚的感念中悄然生长。
第四条:从包容里修,人心就像容器,狭隘者容不下半点的纷忧,终被琐事困局,格局越大承载的福气便会越厚重,海纳百川有容乃大,心宽一寸,路宽一仗,福厚一分。
福运从不在别人的评价里,而藏在自己的方寸心间,心若向阳自带光芒,万事皆顺,心若放宽前路坦荡福气绵长。修好本心在自己的世界里熠熠生辉。
与子书:自信的本质就是大量的练习,大量的研究,不断的重复,不断的坚持,古人讲:厚积才能薄发,不积跬步无以至千里,所以想要变强,就要一次又一次练习,练到举手投足都自带从容,练到旁人以为你天生如此。记住人生没有白走的路,没有天赋那有重复。
与子书:你见过哪个活得开心的人,总是指责别人的;你见过哪个活得通透的人,总是争个对错的;你见过哪个内心富足的人,总是在否定他人的;幸福的人忙着感受生活,因为他的注意力在享受上,而不是在审判上。通透的人不争对错,因为他知道对错是立场不是真理。
与子书:世界上最可贵的两个词:一个叫认真;一个叫坚持。认真的人改变了自己,坚持的人改变了命运。很多事不是看到了希望采取坚持,而是坚持了才有希望。
与子书:四个字"尖斌卡引";尖:能大能小,真君子;斌:能文能武,是英才;卡:能上能下,见格局;引:能屈能伸,福自来。
世界上最可贵的两个词:一个叫认真;一个叫坚持。认真的人改变了自己,坚持的人改变了命运。很多事不是看到了希望采取坚持,而是坚持了才有希望。
与子书:牛仔,人生很长,工作再忙、事儿再大,也别拿身体换前程,人拼到最后,拼的都是身体。千万不要仗着年轻就随便造,熬夜、乱吃、久坐等,看似没事,却都是在透支。健康不是小事,是一切的根基。你平平安安、健健康康,比什么都重要。身体永远是第一位的。没了健康,再拼再忙都没用,照顾好自己,就是对自己、对家里最大的负责。2026年2月25日,教育部召开深入落实"健康第一"工作部署会(2026年"新春第一会"),健康第一成为国民生活的主旋律。
与子书:毛主席四句话解决生活中一个人90%以上的焦虑:
- 第一句话越是形势不好,越要有战略定力;不要跟着别人去抱怨;别人抱怨的时候,脑袋已经出了问题。
- 第二句话积极的想办法才会有办法,只有相信没有不能解决的问题才有能力解决一切问题。
- 第三句话不要一听到和自己不同的意见就生气,认为是不尊重自己,这是以平等的心态带人的条件之一。
- 第四句话一个矛盾克服了,又一个矛盾产生了,在任何时间、任何地方任何人身上总是有矛盾存在,没有矛盾就没有世界。
与子书:世界上最美的相遇是遇见更好的自己!
一、《心经》——好心态精髓7个字(观音菩萨开悟的心得佛:有智慧的人):观自在,五蕴(人或肉身)皆空。
- 1.一切都有缘起,不是空穴来风,一切都是最好的安排,学会坦然接受。
- 2.一切都会过去,过去了的便是空空如也,没有永恒不变的,要好好珍惜当下活在当下。
- 3.一切都要向美好处努力,保持一颗空灵阳光的心态最重要。时时观照让自己保持那颗空灵阳光的心,看到希望和光明,便会获得大自在就远离了痛苦,这就是正确的生活方式。
二、《金刚经》——好行为精髓三个字:善护念。(释迦摩尼佛开悟的心得)真正的佛陀是人不是神。干好普通事,做好平凡人,用火热之心做善良之事。
三、《西游记》——好方向精髓九个字(唐三藏开悟的心得)跟对人、做对事、走对路。
诚是立身之本,有信仰度,圆通万事。人一生要有美好的愿望,把愿望提升到信仰的高度。
一是工作学习不仅是为获得生活的食粮,工作学习的意义在于其中隐藏着磨砺心志、塑造灵魂、具备沉稳而不摇摆厚重人格魅力的巨大力量,这就是工作学习行为的神圣性,工作学习是人生最尊贵、最重要、最有价值的行为,能使人形成有深度的正确的劳动观和人生观,工作学习就是实现自我、完善人格"精进"最好的修行道场。
二是工作学习中有痛苦和烦恼,有顺境和逆境,但无论怎样,都要抱着积极的心态朝前看,任何时候都要认真工作学习,持续努力,这才是最正确的,也是最重要的,就能扭转你的人生,就能带来不可思议的好运,工作学习现场有神灵。
三是一个人如果不爱工作学习丧失热情,长期持续一种颓废的情绪和无聊的生活,你不但不会成长,而且会丧失自己人性中那些美好的东西,将找不到人生和工作的意义,努力工作学习的背后隐藏着快乐和欢喜。
四是人的烦恼据说有108种之多,其中"欲望、恼怒、愚智"这三者是让人陷于烦恼的最厉害的东西。人是不幸的动物,生活中总是被"三毒"支配。独一无二的方法就是努力工作学习让毒素稀释,这也是人真正的能力。
与子书:在外不要逞强,高的还有更高的,马上还有舞刀的,强人面前三尺让,菩萨都是低头相。弱者易怒如虎,强者平静如水,一个人豁达的背后是实力也是格局。
与子书:毛主席四句话解决生活中一个人90%以上的焦虑:
- 第一句话越是形势不好,越要有战略定力;不要跟着别人去抱怨;别人抱怨的时候,脑袋已经出了问题。
- 第二句话积极的想办法才会有办法,只有相信没有不能解决的问题才有能力解决一切问题。
- 第三句话不要一听到和自己不同的意见就生气,认为是不尊重自己,这是以平等的心态带人的条件之一。
- 第四句话一个矛盾克服了,又一个矛盾产生了,在任何时间、任何地方任何人身上总是有矛盾存在,没有矛盾就没有世界。
与子书:牛仔,人生很长,工作再忙、事儿再大,也别拿身体换前程,人拼到最后,拼的都是身体。千万不要仗着年轻就随便造,熬夜、乱吃、久坐等,看似没事,却都是在透支。健康不是小事,是一切的根基。你平平安安、健健康康,比什么都重要。身体永远是第一位的。没了健康,再拼再忙都没用,照顾好自己,就是对自己、对家里最大的负责。2026年2月25日,教育部召开深入落实"健康第一"工作部署会(2026年"新春第一会"),健康第一成为国民生活的主旋律。
与子书:一年之计在于春,一生之计在于勤;春天是播种的季节,更是奋斗的季节。一年春作首,万事行为先。新一年"开好局起好步"要做到三个干:把千头万绪事干顺,把平凡小事干精,把本职工作干优。把简单事情做好就是不简单,把平凡的事情做好就是不平凡。今天我讲两个方面:
一是喜欢一本书:作家梁爽《把自己重养一遍》。
好好爱自己,把日子过成自己喜欢的模样。
你需要的不是被爱,而是好好爱自己,就是送给自己最大的礼物。远离负能量,坚守健康的心态,健身、读书、旅行,学会独处。不内耗,不较劲,不攀援,不依赖。生命啊,不过是一场路过。其实啊,其实呢,也是一场对自己的负责。人活在这个世上,你首先要成为自己,然后才为任何人。
爱自己——
一是养好自己的身体,身体是生命的支柱,也是你幸福生活的源泉。让自己健康的生活才是一个人最大的拥有。台湾作家三毛说:今日的事情,尽心、尽意、尽力去做了,无论成绩如何,都应该高高兴兴的上床睡觉。美好的人生,就是白天脚踏实地,晚上"觉"踏实地。
二是学会管理自己的情绪。心平能愈三千疾,心通可通万事理。心福可染三千愁心和可容万粒尘。成年人的世界里,情绪稳定才是一个人最大的修养。只有内心平静平和,才能感受到生活的幸福和快乐。
三是学会调整自己的心态。好心态是治愈一切的良药,只有让心快乐了,人才会变得阳光。生活中的凡事,多向好的方向努力,不悲观,不抱怨,少想多做,你的人生就会变得越来越顺。
任何时候一定都不要忘了,永远不要放弃成长。永远要有自己的翅膀,你曾经跨越高山去寻找真爱,而真正的爱是走向自己,拥抱自己。好好爱自己,把日子过成自己喜欢的模样,自己就是自己最好的再生父母。
二是爱上一句话:北大首任校长严复说过的这段话:"物质的贫穷,能摧毁你一生的尊严;精神的贫穷,能耗尽你几世的轮回。世上没有白走的路,人生没有白读的书,你走过的路,你读过的书,会在不知不觉中改变你的认知,悄悄帮你擦去脸上的无知和肤浅。读书,世界就在眼前,不读书,眼前就是世界。读书不一定能让你前程似锦,功成名就,但至少可以让你出言有尺,嬉闹有度,说话有德,做事有余。这世间,物质贫穷不可怕,最可怕的是精神上的贫穷。真正的穷人,一定穷在他的认知、思维和价值观。没有谁的生活没有烦恼,唯有阅读是最好的解药。书中不一定有黄金屋,但一定会认识更好的自己。
鸟欲高飞先振翅,人求上进先读书。
不负春光起好步,只争朝夕开新局。树的方向风决定,人的方向自己定,生活就是我们为之奋斗的事业!在任何时候,干任何事,都要吃得下苦耐得住烦,一要勤二要实。"勤"字诀多一些努力,便多一些成功的机会。无数事实证明:成功的最短途径是勤奋。不要光耍嘴皮子,不要好逸恶劳,勤字当头,苍天不负有心人,天道酬勤!懒能致笨。"实"字诀。踏踏实实做人,实实在在办事。任何一个双手插在口袋里的人,都爬不上成功的梯子。给人留下一个实在的形象,给自己的成功增添一份夯实的基础,从实际出发,对自己负责。
你想聪明吗?跑步吧!你想健美吗?跑步吧!你想强壮吗?跑步吧!如果你要卓越,读书吧!如果你要高尚,读书吧!如果你要明智,读书吧!











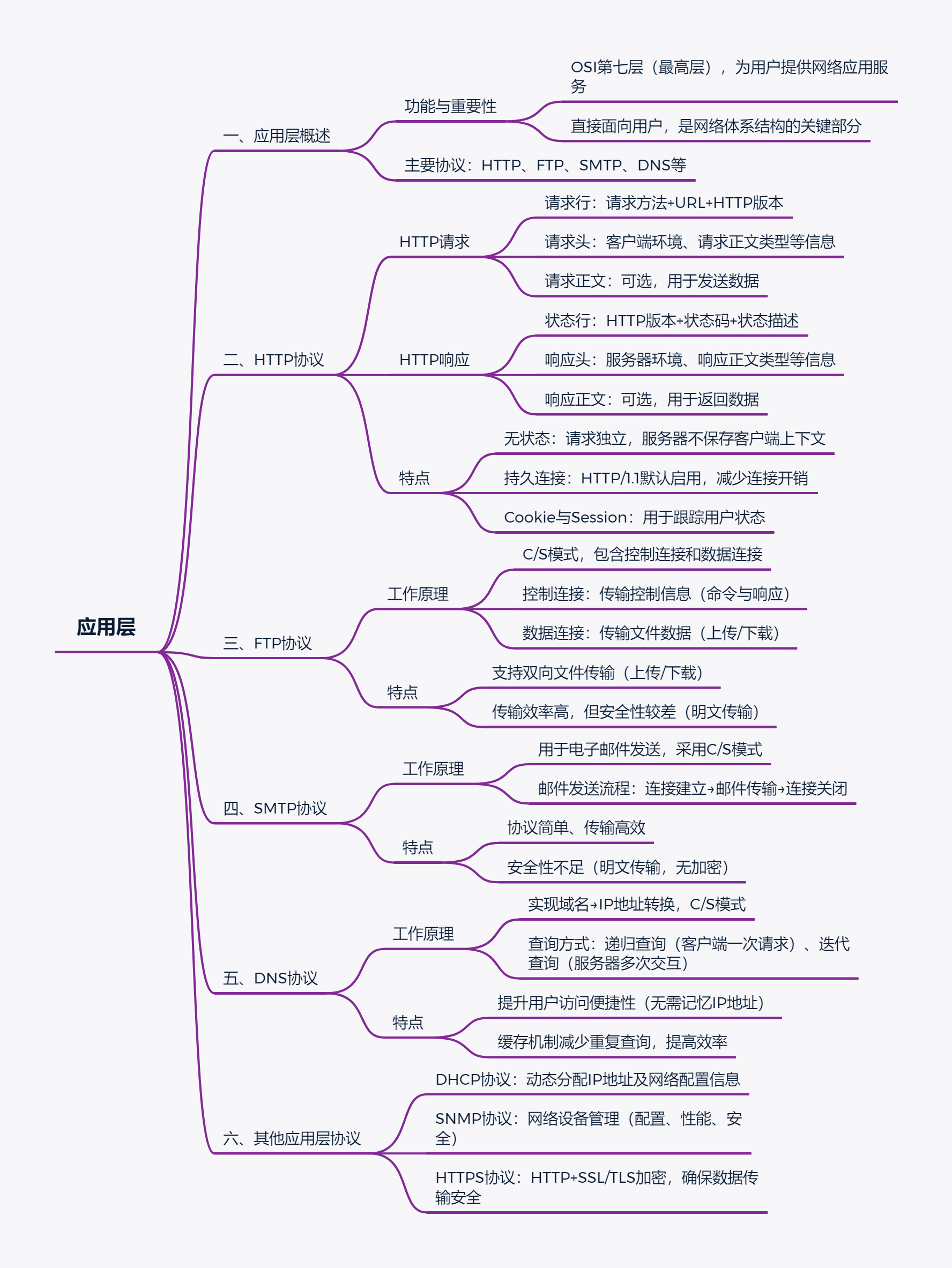
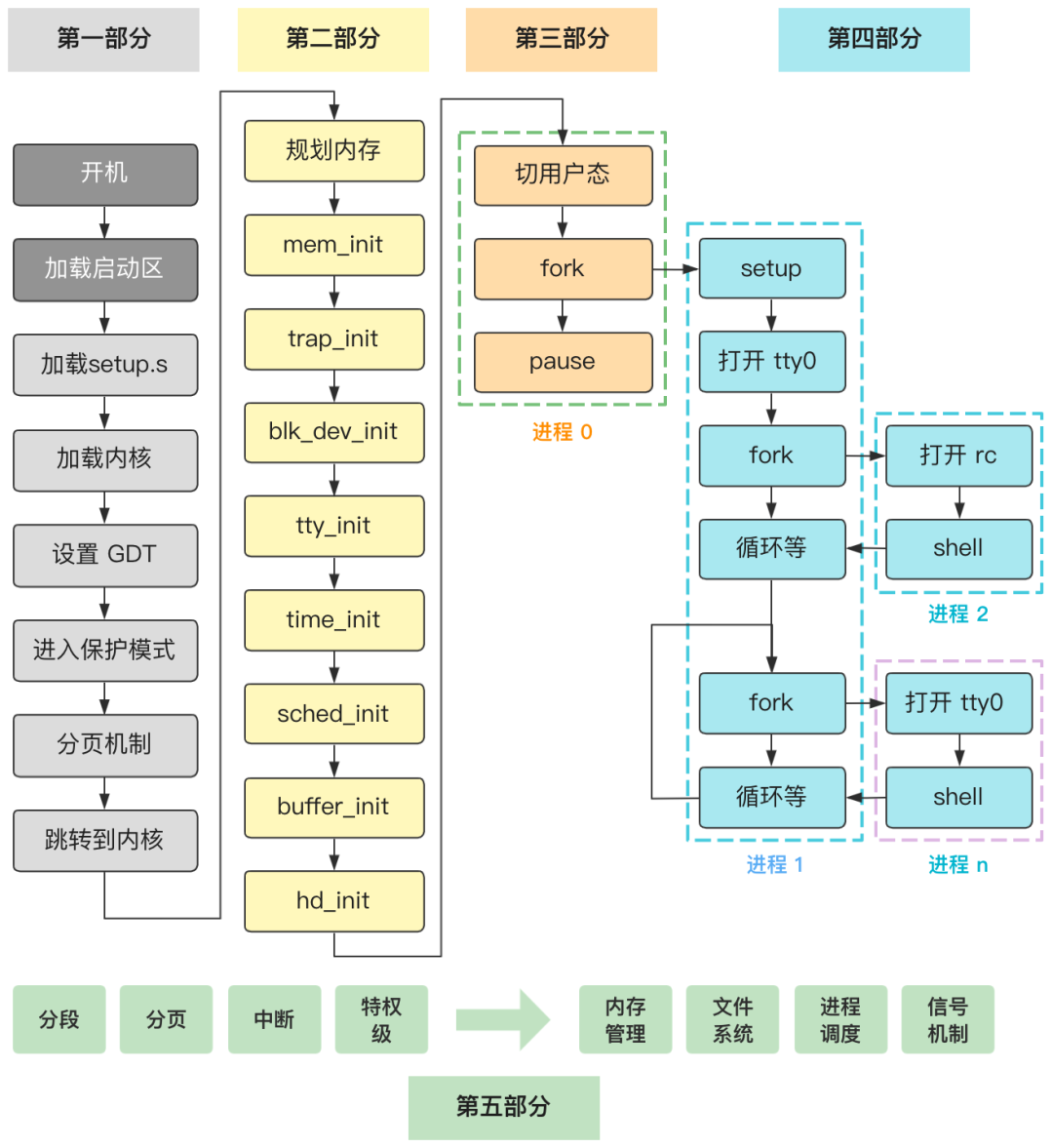 ]]>
]]>
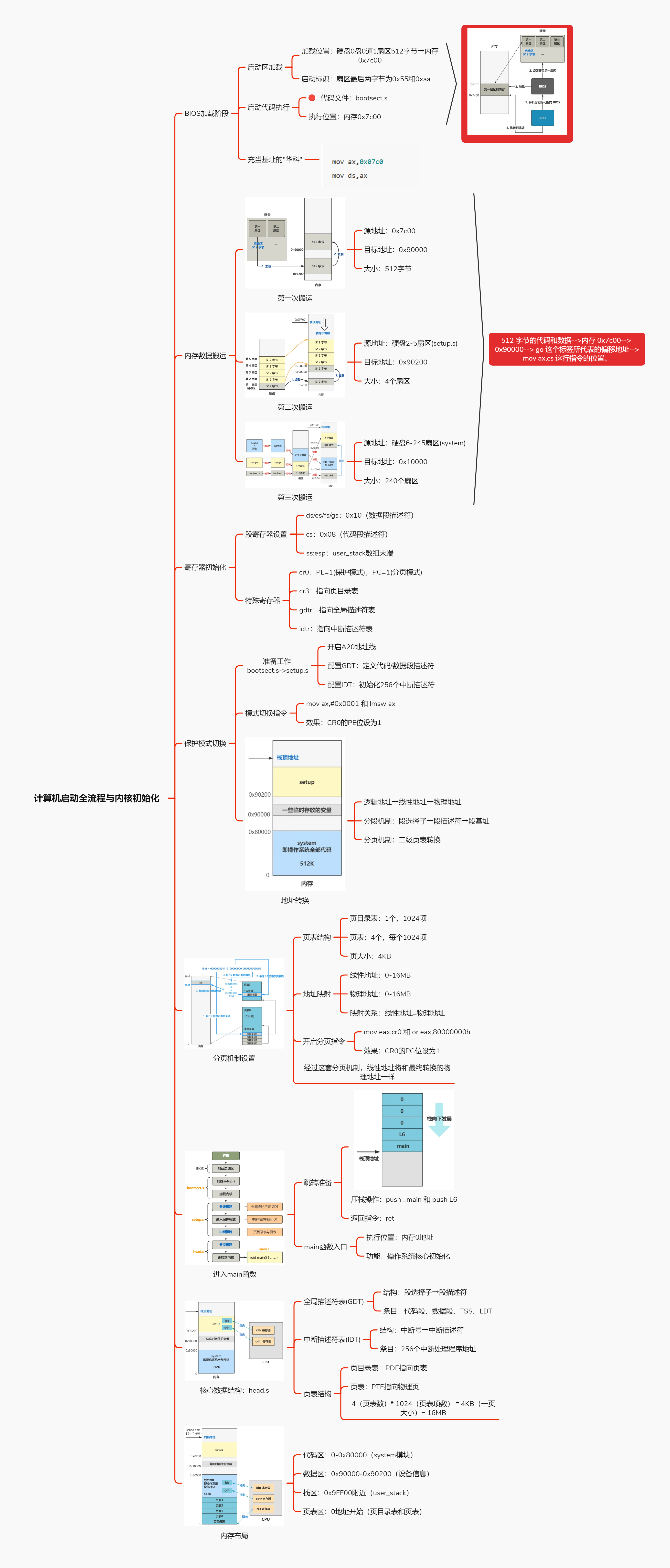 ]]>
]]> ]]>
]]> ]]>
]]> ]]>
]]> ]]>
]]> ]]>
]]> ]]>
]]> ]]>
]]> ]]>
]]> ]]>
]]> ]]>
]]>
 ]]>
]]>