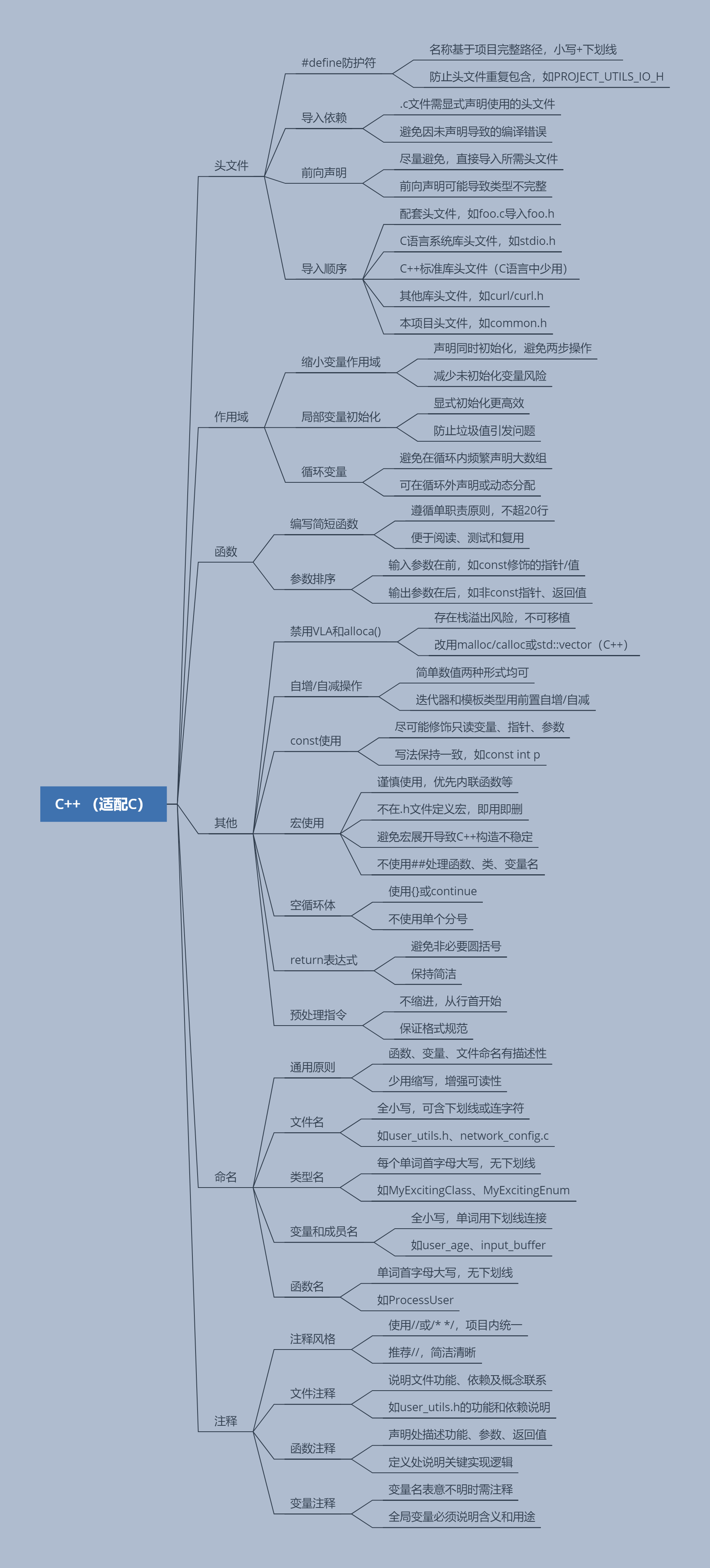
Google C 语言编程风格指南学习笔记:从规范到实践
导言
作为 C 语言开发者,遵循统一的编程风格不仅能提升代码可读性,还能减少潜在错误。本文基于 Google C/C++ 风格指南(侧重 C 语言部分),结合实际开发场景,梳理核心规范与实践建议,助你写出更专业、更健壮的 C 代码。
一、头文件:代码的 “入口守卫”
头文件是 C 语言模块化的核心,其规范直接影响代码的可维护性与编译效率。
1. 头文件防护符:防止重复包含
规则:每个头文件必须用#ifndef/#define/#endif防护,防护符名称应基于文件在项目中的完整路径(小写 + 下划线连接)。
原因:避免同一头文件被多次包含导致的类型重复定义错误。
示例(错误→正确):
1 | // 错误:防护符与文件路径无关,易冲突 |
2. 头文件导入顺序:明确依赖关系
规则:按以下顺序导入头文件(从 “最相关” 到 “最通用”):
当前文件对应的配套头文件(如foo.c导入foo.h);
C 语言系统库头文件(如stdio.h、stdlib.h);
C++ 标准库头文件(若混合编程,C 语言中一般不涉及);
其他第三方库头文件(如curl/curl.h);
本项目其他头文件(如common.h)。
原因:快速定位依赖关系,避免因顺序问题导致的编译错误(如系统库未提前包含)。
3. 避免前向声明,优先显式包含
规则:C 语言中尽量不使用前向声明(如struct Foo;),直接包含所需头文件。
原因:前向声明仅声明类型存在,无法保证类型完整性(如结构体成员),可能导致编译错误或未定义行为。
反例:
1 | // utils.h(未包含foo.h) |
二、作用域:让变量 “活在需要的地方”
C 语言的作用域规则相对简单,但合理控制变量生命周期能显著提升代码质量。
1. 缩小变量作用域:声明即初始化
规则:变量应在最小作用域内声明,且声明时显式初始化(避免 “声明→赋值” 两步操作)。
原因:未初始化的变量可能残留垃圾值,导致不可预测的行为;局部变量作用域越小,越容易追踪其状态。
示例:
1 | // 反例:变量作用域过大,且未初始化 |
2. 循环中的变量:避免构造 / 析构开销(C 语言特化)
规则:在循环中声明临时变量时,优先使用作用域仅限循环的表达式(如 for 循环的初始化语句)。
原因:C 语言虽无 C++ 的构造 / 析构机制,但频繁在循环内声明大数组或复杂类型(如结构体)会浪费内存,甚至导致栈溢出。
示例:
1 | // 反例:每次循环都声明大数组(栈空间可能不足) |
三、函数:简短、清晰、职责单一
函数是代码的 “基本单元”,其设计直接影响可读性与可维护性。
1. 编写简短函数:单职责原则
规则:函数应功能单一,避免 “大而全” 的逻辑(理想长度:不超过一屏,约 20 行)。
原因:短函数易读、易测试、易调试;职责单一的函数更易复用。
反例:
1 | // 反例:一个函数处理输入、计算、输出,逻辑混乱 |
2. 参数排序:输入在前,输出在后
规则:函数参数中,仅输入参数(如 const 修饰的指针 / 值)放在输出参数(如非 const 指针、返回值)之前。
原因:明确参数用途,调用时更易区分 “传入值” 和 “修改值”。
示例:
1 | // 反例:输入输出参数混杂,调用时易混淆 |
四、其他核心规范:细节决定成败
1. 禁止变长数组(VLA)与 alloca ()
规则:禁止使用变长数组(如int arr[n],n为变量)和alloca()(栈动态分配),改用malloc/calloc或std::vector(C++)。
原因:VLA 和alloca()可能导致栈溢出(栈空间有限),且行为不可移植(部分编译器不支持)。
替代方案:
1 | // 反例:VLA可能导致栈溢出 |
2. const:让代码更健壮
规则:尽可能使用const修饰只读变量、指针或函数参数,保持代码一致性(所有const写法统一,如const int p或int const p)。
原因:const能明确数据是否可修改,避免意外修改导致的 bug;编译器会检查const约束,提前拦截错误。
示例:
1 | // 反例:未使用const,可能意外修改只读数据 |
3. 宏:谨慎使用,优先替代方案
规则:
避免在.h文件中定义宏(易引发重复包含);
临时宏需 “即用即删”(#define后立即#undef);
用内联函数、枚举、常量替代简单宏(如#define MAX(a,b) ((a)>(b)?(a):(b))易引发副作用)。
示例(宏的风险):
1 | // 危险宏:参数可能被多次求值(如i++) |
五、命名:让代码 “自解释”
好的命名能减少 70% 的注释需求,是代码可读性的第一保障。
1. 文件名:小写 + 下划线,清晰描述功能
规则:文件名全小写,可用下划线(_)或连字符(-)分隔(如user_utils.h、network_config.c)。
原因:跨平台兼容(部分系统对大小写敏感),且直观反映文件内容。
2. 类型名:大驼峰,突出 “类型” 属性
规则:类型名(结构体、枚举、联合体)每个单词首字母大写,无下划线(如UserInfo、ErrorCode)。
示例:
1 | // 结构体类型名 |
3. 变量 / 参数 / 成员名:小写 + 下划线,描述用途
规则:变量、函数参数、结构体成员名全小写,单词间用下划线连接(如user_age、input_buffer)。
示例:
1 | void process_user(UserInfo* user) { |
六、注释:让代码 “会说话”
注释不是代码的 “装饰品”,而是 “说明书”,需精准传递关键信息。
1. 注释风格:统一即可(// 或 //)
规则:项目内统一使用//(行注释)或/ * * /(块注释),推荐//(更简洁)。
2. 文件注释:说明整体功能与依赖
规则:每个头文件 / 源文件顶部添加注释,说明文件用途、核心功能及与其他模块的关系。
示例(user_utils.h):
1 | /* |
3. 函数注释:声明处写 “功能”,定义处写 “实现”
规则:
函数声明(头文件)注释:描述功能、参数含义、返回值;
函数定义(源文件)注释:描述关键实现逻辑(如算法、边界条件)。
示例:
1 | // 头文件声明(功能) |
总结:风格即质量
Google C 风格指南的核心是 “一致性” 与 “可维护性”。通过规范头文件、作用域、函数设计、命名与注释,能让代码更易读、易调试、易协作。记住:写代码是写给 “未来的自己” 和 “团队伙伴” 看的,遵循规范不仅是对他人负责,更是对自己的职业发展负责。从今天开始,在新代码中实践这些规范,逐步将习惯转化为肌肉记忆 —— 你会发现,代码质量的提升,从 “遵守规则” 开始。